
Reverse tunnelling is a technique used to ‘sneak into’ a secured network by hiding applications within traffic which originates from within the network.
Reverse Tunnelling
A bit of background
Before we can get to the topic of reverse tunnelling, lets refresh our understanding on data traffic on network.
Data transmitted over a network is broken down into packets. Identifying attributes such as source IP address, source port, destination IP address, and destination port allow the Internet infrastructure to direct the packets to the intended host and service. For example, when a browser makes a web request, the source IP address would be the IP address of the client machine, the source port would be a random ephemeral port (1024–65535), the destination IP address would be the IP address of the host running the web server and the destination port would be TCP 80 or 443 depending on the application/protocol.

In the above example, the connection is initiated from the browser to the web server.
A note about public and private IP addresses and NAT
The limited availability of IPv4 addresses gave rise to the need to share IP addresses with multiple devices. A single public IP address is usually divided into multiple private IP address using a mechanism known as Network Address Translation or NAT.
In the scenario discussed earlier, the source IP address would be a private IP address when the packet leaves the client machine. However, when the packet reaches the Internet, the NAT device would have changed the source IP address to the public IP address. The web server only sees and replies to the public IP address. The NAT device translates the destination IP address in the reply packet to the private IP address of your host using the destination port on the reply packet.
Hence, if a packet originates from the internet, intended to reach your host which is behind a NAT device, the NAT device will not know which private IP address to send the packet to.
A note about stateful firewalls
Firewalls are devices used to secure the hosts on a network against attacks from the outside.
Traditionally firewalls were configured with access control lists which had information such as IP address, port etc. which were used to filter the flow of traffic from both sides of a network to the other.
However, newer generations of firewalls known as stateful firewalls can track whether a packet coming from outside the network is a reply to an earlier request from within the network. This has greatly improved the efficiency of the firewalls.
If a packets originates outside a network, and is not a reply to an earlier request, it is blocked by the stateful firewall, unless specifically configured otherwise.
Reverse Tunnelling Use Case
Technologies such as NAT and stateful firewalls make it difficult for threat actors to get into hosts which are on a closed network and are not exposed to the internet.
Here a clever threat actor can use reverse tunnelling to get access to these devices.
How Reverse Tunnelling works
For reverse tunnelling to work, there are a few prerequisites.
- Initial Access – Well configured stateful firewalls only allow inbound packets if they are replies to traffic originated from within the secured network (zone). Thus the threat actor needs a program inside the network to external communication from within the network for reverse tunnelling to work.
- Command-and-Control Server – This is a host outside the network which is reachable from within the network. In the case of the internet, this device needs should have a single public IP/ port which is reachable on the internet.
- Application/Protocol – An application or protocol which is used in reverse tunnelling should be something that the firewall would allow from inside the network to outside. The most common example of this would be HTTP(s) or DNS. SSH is also a popular popular protocol when it comes to reverse tunnelling.
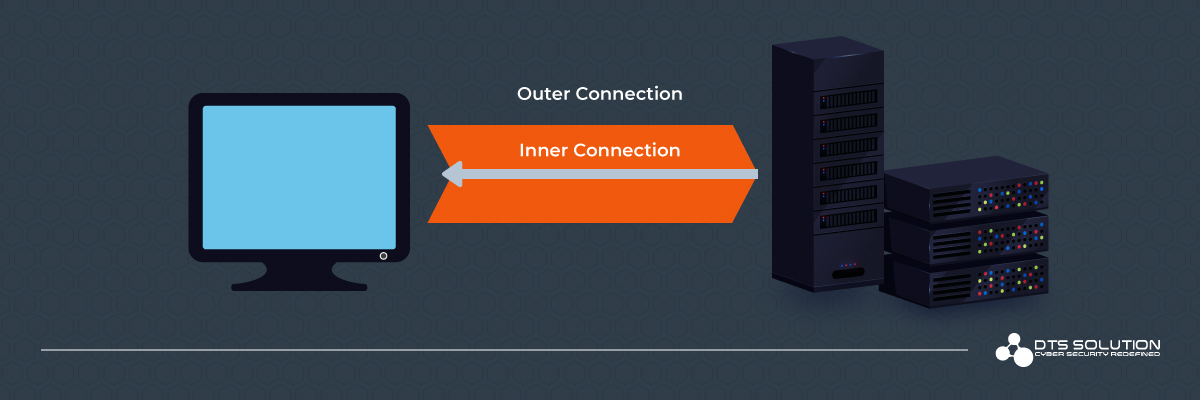
Reverse tunnelling works by creating a connection which originates from a device inside a secured network to the command and control server outside the network.
When setting up the connection the device inside the secured network creates a local port and a remote port. The device instructs the command and control server to listen for connections on the remote port and forward any connection that it receives on that port back to the device inside the secured network on the local port. On the command and control server, the remote port acts as a local port where it listens for connections.
The diagram above represents the connections involved in reverse tunnelling.
Consider the connections as tubes. The bigger tube represents the connection that the internal client makes to the external server. The external server forwards connections that it receives on the specified port via the connection represented by the inner tube.
Once the reverse tunnel has been established, the threat actor can connect to the command and control server which he controls, on the remote port specified by the device inside the secured network. This connects the threat actor to the device inside the secured network.
Impact
Once inside the network, what can the threat actor do?
This would depend on the initial access, specifically the user account which was used to run the application which created the tunnel.
If a limited user account was used to create the tunnel, the threat actor who now has access to the system would only have the permissions of the limited user. However, if a user account with administrative privileges was used, the impact would be much more severe. For example, below are just a few of the possible options that the threat actor now has.
- Create user accounts
- Disable security software
- Install system services / modify registry to maintain access across reboots
- Discover other systems on the internal networks and compromise them
- Deploy ransomware
- Exfiltrate data
- The possibilities are endless at this point.
Mitigation
Challenges
- The traffic looks legitimate to a firewall.
- Reverse tunnelling is not dependent on a specific application, port or protocol. Generally commonly used protocols such as HTTP, HTTPs , SSH, DNS etc are used for reverse tunnelling. Since the traffic originates inside the network, firewalls have a hard time identifying.
- Tunnelling traffic over protocols such as SSH, HTTPS etc, have encryption which makes it difficult for security devices to see the traffic inside the tunnel.
- Currently available security measures for reverse tunnels tend to be application/protocol specific. For example, security products now provide protection against DNS tunnelling or SSH tunnelling. However, the threat actor can use a different application/protocol for the tunnel.
Mitigation Strategy
A holistic approach is required to mitigate reverse tunnelling as attack technique.
- As we discussed above, initial access is a prerequisite to establish a reverse tunnel. A threat actor could gain access to the network using a number of ways. It could be argued that the most vulnerable attack surface is people. Social engineering is the tactic of exploiting people as an attack surface.
Phishing is indisputably the most common technique used for this.
Phishing emails trick the reader into clicking on a link or attachments that delivers the payload which will create a reverse tunnel to the command-and-control server.
Email security has come a long way in reducing the risk of phishing attacks. However, as security evolves, so do the tactics and techniques used by threat actors.
Hence, there is no substitute for proper education and awareness of employees with regards to cyber security. - The command-and-control server used by a threat actor is usually set up only for the duration of the attack. Hence, there is a good chance that the public IP address used is newly assigned. There is also a good chance that the threat actor employs the services of anonymous hosting providers. In both these cases the integration of a good threat intelligence system with sandboxing capabilities to your cyber security infrastructure can be invaluable.
- In the case of a newly assigned public IP address, the threat intelligence system should identify the IP address as bogon (newly assigned and hence not yet trustworthy).
- In the case of an anonymous hosting provider, there is a good chance that the threat intelligence system would tag the IP address as unsafe if it has been reported in the past.
- Today’s next generation firewalls (NGFWs) or intrusion detection/prevention systems (IDS/IPS) have capabilities such as SSL/TLS decryption and machine learning. These could prove effective in identifying tunnels using behaviour analysis. However, both of these are highly resource intensive features and only available with high end models of the firewalls or IDS/IPS.
- The final ingredient in mitigation would be the Security Operations Center. The SOC gathers information from the multiple sources discussed above and correlates the information to create an actionable holistic picture. This plays a vital role in detecting the attack at different stages of the kill chain and staying one step ahead.
Reverse tunnelling in itself does not constitute an attack. It is a step in the attack kill chain which plays a vital role in the success of the attack. Different tactics and techniques work together to bring an attack to completion and cause impact to the target.
At HAWKEYE, we use sophisticated data analysis, machine learning and correlation techniques to generate timely actionable intelligence to ensure that attacks are detected early in its life cycle and the tactics and techniques at different stages of the attack are immediately identified and mitigated thus preventing the attack life cycle from reaching completion and avoiding the impact.
This post is written by Sandeep Renjith, Cyber Security Analyst at DTS Solution